Probability box¶
A conspicuous problem in probability distribution elicition, for example in probabilistic modelling analysis, is that the specification is typically precise, despite hardly justified by empirical informtion in many cases.
Attention
epistemic uncertainy remains on the shape, parameters, and dependencies of the distributions.
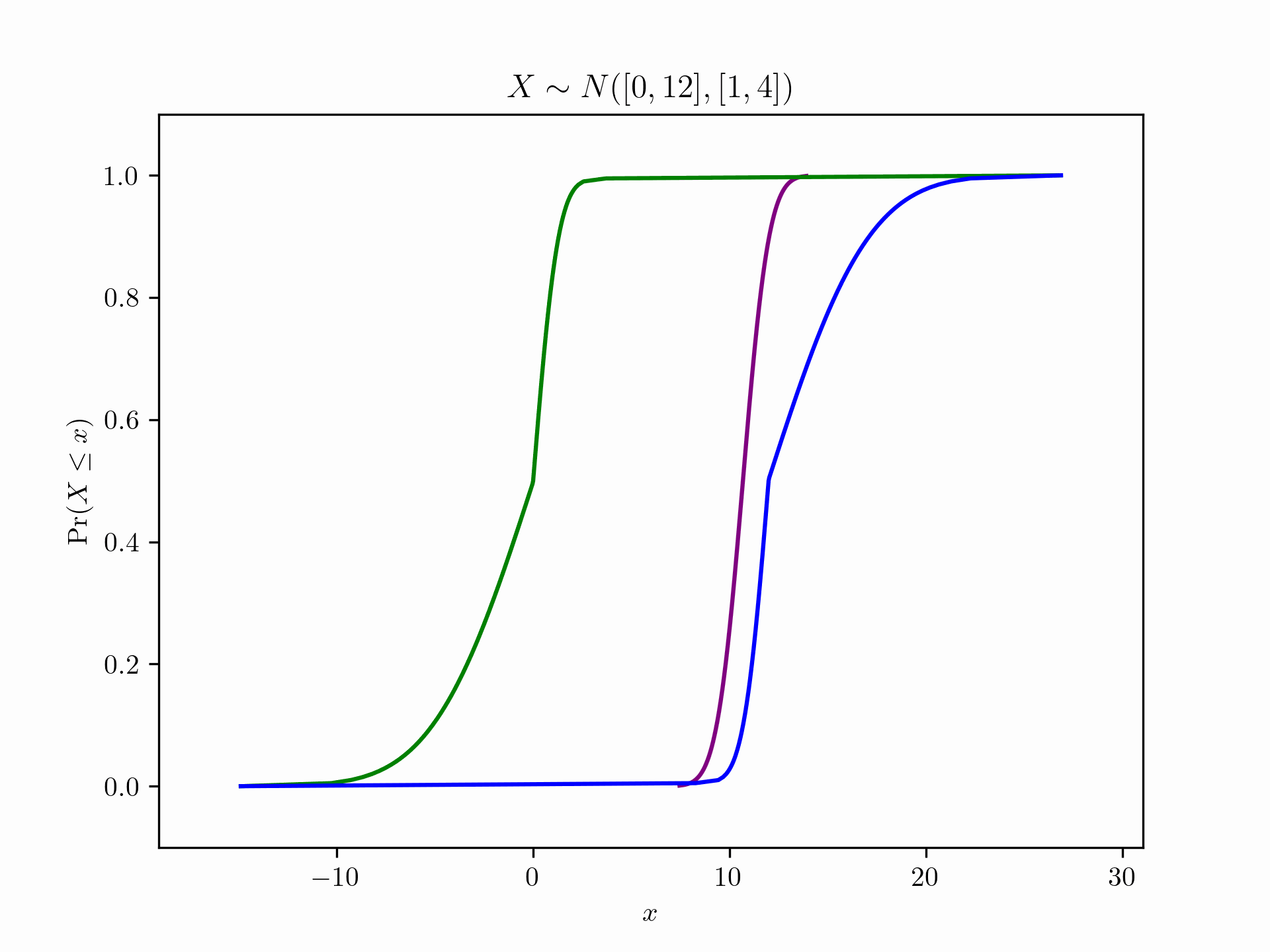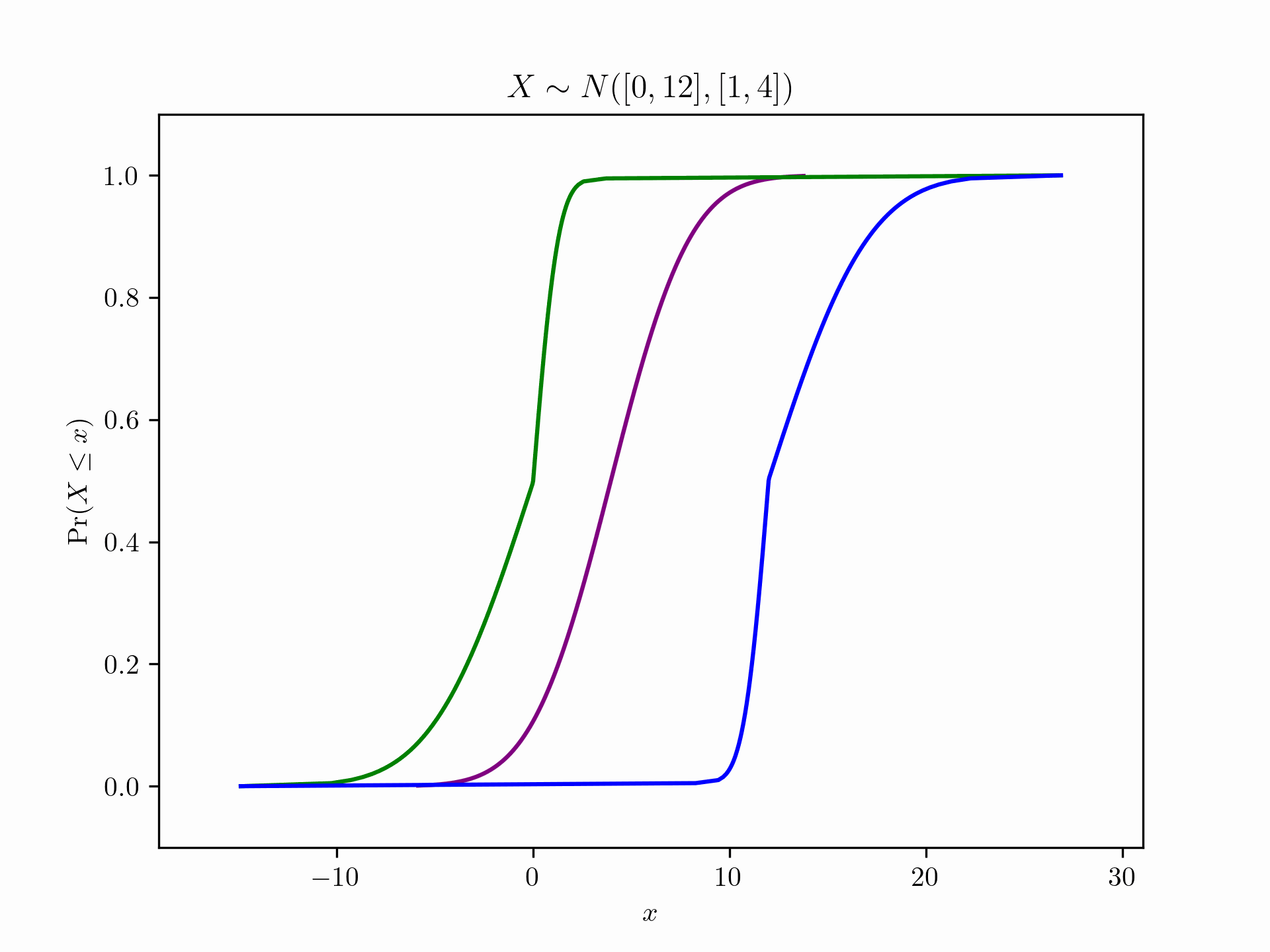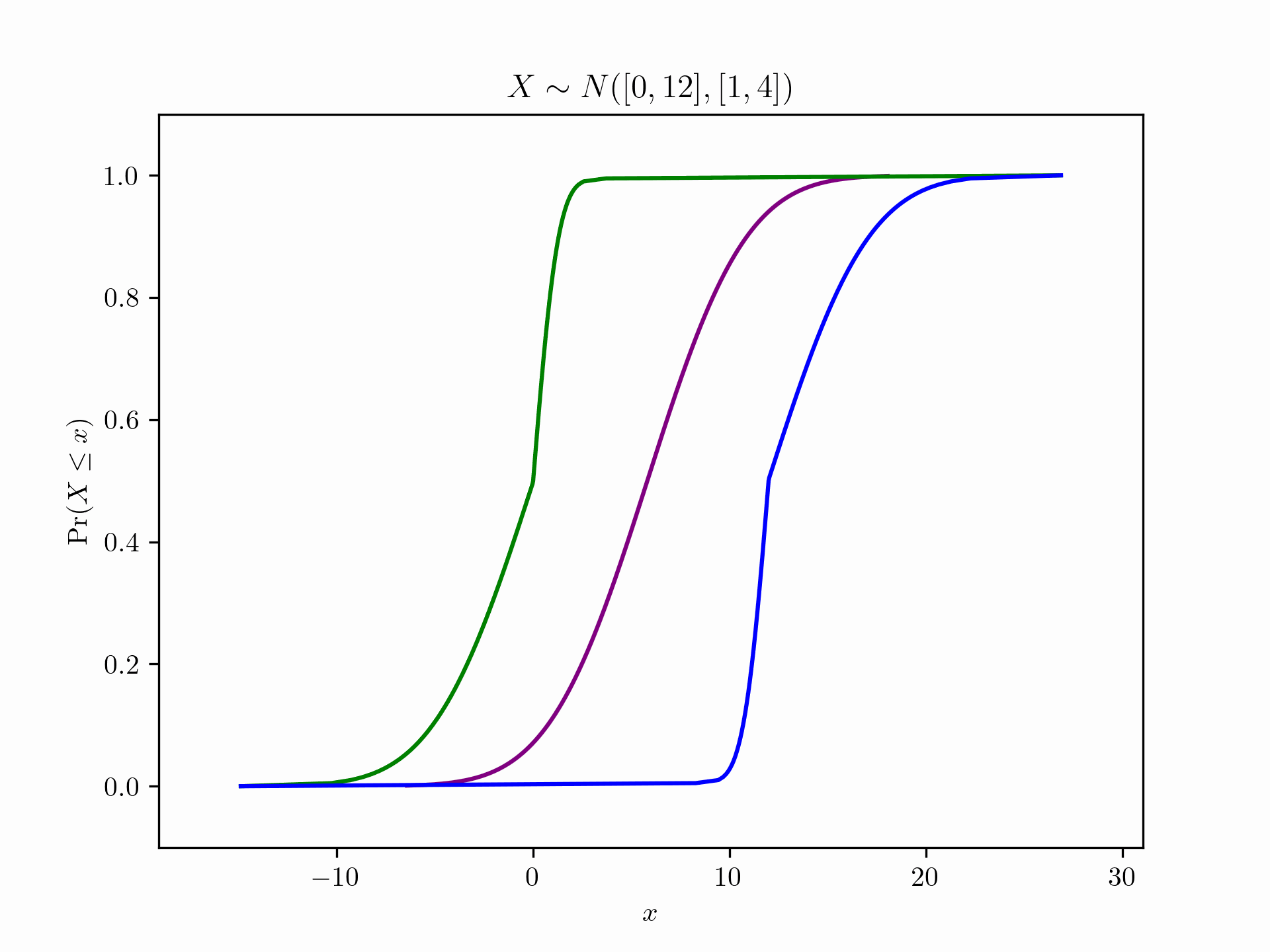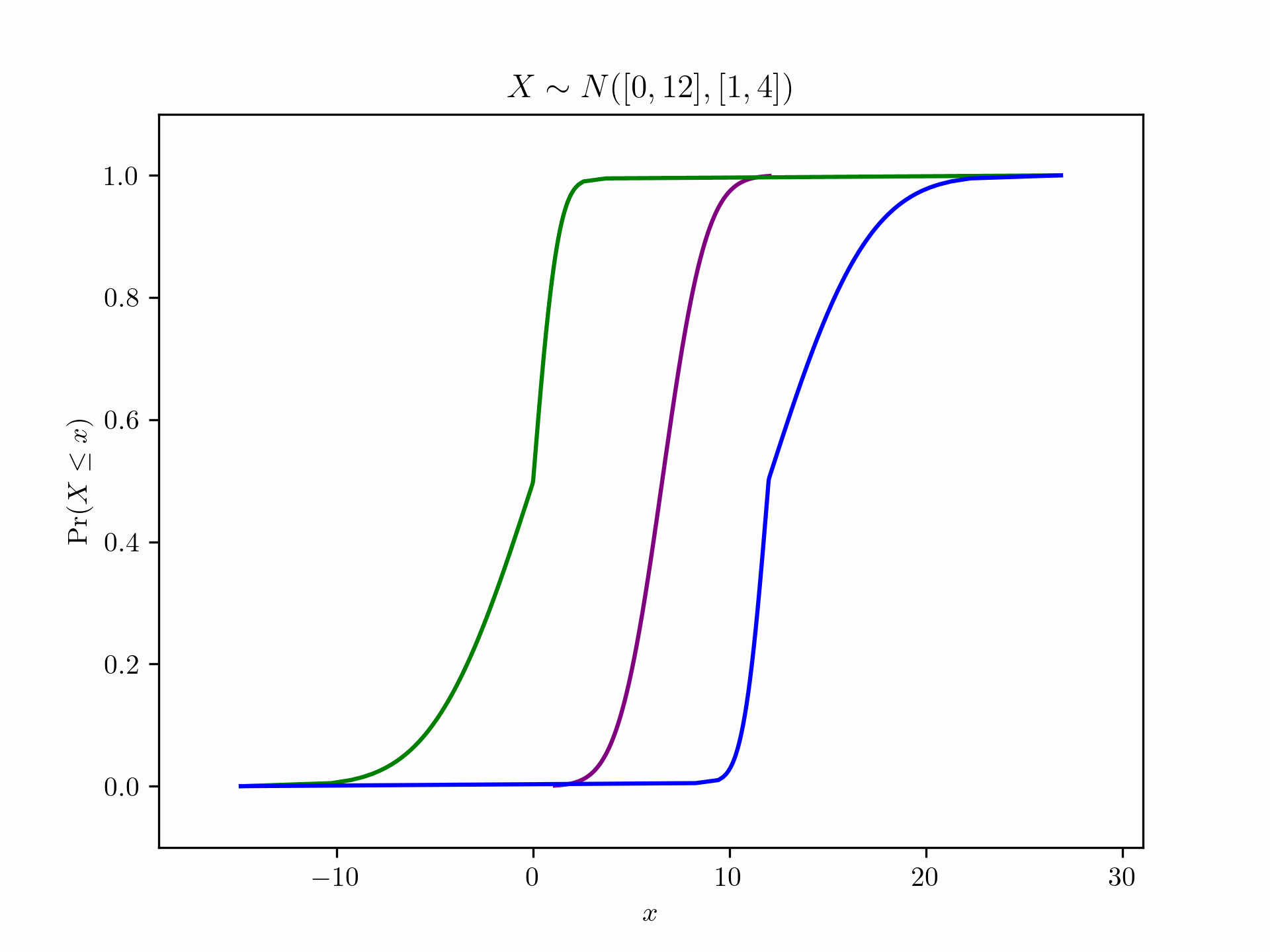
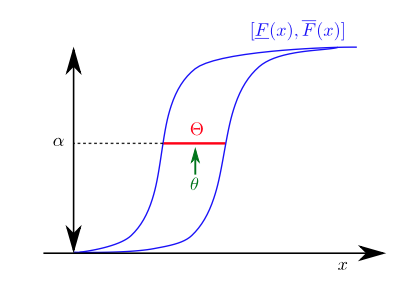
Probability box (abbreviated as p-box) essentially represents bounds on the cumulative distribution function (c.d.f) of the underlying random variable. Let \([\overline{F}, \underline{F}]\) denotes the set of all nondecreasing functions from the reals into \([0,1]\) such that \(\underline{F} \le F \le \overline{F}\). This means that, \([\overline{F}, \underline{F}]\) denotes a p-box for a random varaible \(X\) whose c.d.f \(F\) is unknown except that it is within the “box” circumscribed by the lower (\(\underline{F}\)) and upper bound (\(\overline{F}\)).
p-box collectively reflects the variability (aleatoric uncertainty) and incertitude (epistemic uncertainty) in one structure for the uncertain quantity of interest. The horizontal span of the probabilty bounds are a function of the variability and the vertical breadth of the bounds is a function of ignorance.
Hint
There is a storng link between p-box and Dempster-Shafer structures (which PyUncertainNumber also explicitly provides support :boom:). Each can be converted to the other. However, it should be noted such translation is not one-to-one.
PyUncertainNumber provides support for p-boxes ranging from characterisation, aggregation, propagation. Go check out these links for details as to the computation with p-boxes. Meanwhile, quick examples are show below:
from pyuncertainnumber import pba
p = pba.normal([0, 12], [1,4])
p.display()