pyuncertainnumber.calibration.data_peeling.peeling¶
Functions¶
|
Data peeling algorithm for constructing a sequence of nested enclosing sets. |
|
Converts the list of indices x into a (nx1) boolean mask, true at those particular indices |
|
|
|
|
|
|
|
Peeling to structure. |
|
|
|
|
|
Module Contents¶
- pyuncertainnumber.calibration.data_peeling.peeling.data_peeling_algorithm(X: numpy.typing.NDArray, tol: float = 0.0001) tuple[list, list]¶
Data peeling algorithm for constructing a sequence of nested enclosing sets.
- Parameters:
X (NDArray) – data set of iid observations
tol (float) – a tolerance parameter determining the minimal size of an allowed enclosing box
- Returns:
- a tuple containing:
- sequence_of_indices (list):
a list (number of levels long) of sets (or list) of indices of heterogeneous size
- sequence_of_boxes (list):
a list (number of levels long) of (dx2) boxes
- Return type:
tuple[list, list]
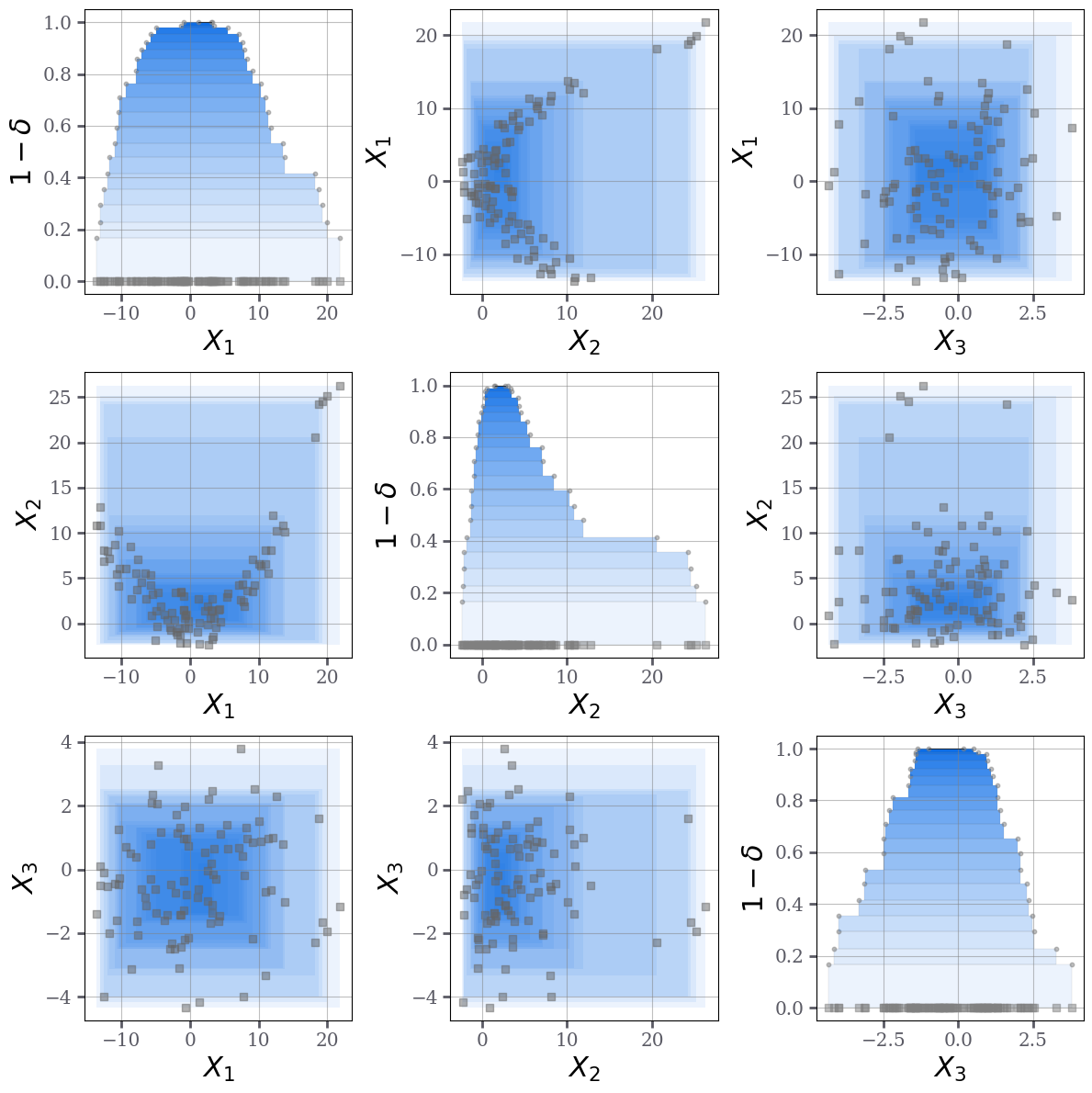
Illustration of the data peeling algorithm.¶
- pyuncertainnumber.calibration.data_peeling.peeling.index_to_mask(x: list, n=100) numpy.ndarray¶
Converts the list of indices x into a (nx1) boolean mask, true at those particular indices
- Parameters:
x (list) – list of indices
n (int, optional) – size of the mask. Defaults to 100.
- Returns:
boolean mask
- Return type:
numpy.ndarray
- pyuncertainnumber.calibration.data_peeling.peeling.make_hashtable(x)¶
- pyuncertainnumber.calibration.data_peeling.peeling.sanity_check(a, b, tol=0.0001)¶
- pyuncertainnumber.calibration.data_peeling.peeling.data_peeling_backward(uy: numpy.typing.NDArray, y: numpy.typing.NDArray = None, boxes: list = None, tol=0.0001) tuple[list, list, list]¶
- Parameters:
uy (NDArray) – (mxd) array of coverage samples output space.
boxes (list) – sequence of boxes, each box is a (dx2) array. Also iterable of interval objects.
- Returns:
- a tuple containing:
a: list (number of levels long) of sets (or list) of indices (heterogeneous size).
b: list (number of levels long) of (dx2) boxes (array-like).
c: list (number of levels long) of indices (input space) conatained in each level.
- Return type:
tuple[list, list, list]
Note
- There are two cases where the peeling algorithm must raise an exception, and they are both linked to the termination of the algorithm.
When the last enclosing set has less samples than the minimum number of support scenarios to determine that set.
When there are enough samples to determine the set but some of them are too close to eachother (even for just one dimension).
While two may be linked to the problem of degeneracy, in this context, it may be best suited to refer to this case as a coverage problem.
- pyuncertainnumber.calibration.data_peeling.peeling.extract_kn(a)¶
- pyuncertainnumber.calibration.data_peeling.peeling.peeling_to_structure(a: list, b: list, kind: str = 'scenario', beta: float = 0.01) tuple[numpy.typing.NDArray, list]¶
Peeling to structure.
- Parameters:
a (list) – (number of levels long) of sets (or list) of indices of heterogeneous size
b (list) – (number of levels long) of (dx2) boxes (array-like)
- Returns:
(lxdx2) array containing the projections of a joint fuzzy number. p: list[float] of length l
- Return type:
Note
Note b may not be boxes, but spheres, ellipses, etc.
Tip
keep b for piping: peeling_to_structure(data_peeling_algorithm(x))
- pyuncertainnumber.calibration.data_peeling.peeling.uniform(lo, hi, N=100)¶
- pyuncertainnumber.calibration.data_peeling.peeling.samples_to_structure(ux: numpy.typing.NDArray, c: list)¶
- Parameters:
ux (NDArray) – (mxd_) array.
c (list) – (number of levels long) subset of indices (input space) conatained in each level.
- Returns:
(lxd_x2) array containing the projections of a joint fuzzy number in the input space.
- Return type:
fx
- pyuncertainnumber.calibration.data_peeling.peeling.width(x: numpy.typing.NDArray)¶
- Parameters:
x – An interval or interval iterable, i.e. an (dx2) array
- Returns:
the width of the intervals
- Return type:
w