pyuncertainnumber.pba¶
Submodules¶
- pyuncertainnumber.pba.aggregation
- pyuncertainnumber.pba.cbox
- pyuncertainnumber.pba.cbox_constructor
- pyuncertainnumber.pba.constructors
- pyuncertainnumber.pba.context
- pyuncertainnumber.pba.core
- pyuncertainnumber.pba.dependency
- pyuncertainnumber.pba.distributions
- pyuncertainnumber.pba.dss
- pyuncertainnumber.pba.ecdf
- pyuncertainnumber.pba.imprecise
- pyuncertainnumber.pba.intervals
- pyuncertainnumber.pba.mixins
- pyuncertainnumber.pba.operation
- pyuncertainnumber.pba.params
- pyuncertainnumber.pba.pbox_abc
- pyuncertainnumber.pba.pbox_free
- pyuncertainnumber.pba.pbox_parametric
- pyuncertainnumber.pba.utils
Attributes¶
Classes¶
Interval is the main class |
|
a base class for Pbox |
|
parametric pbox |
|
Class for Dempester-Shafer structures. |
|
Class for Dempester-Shafer structures. |
|
Two signatures are currentlly supported, either a parametric specification or from a nonparametric empirical data set. |
|
Two signatures are currentlly supported, either a parametric specification or from a nonparametric empirical data set. |
|
Joint distribution class |
|
Empirical cumulative distribution function (ecdf) class |
|
Dependency class to specify copula models. |
|
a handy tuple of eCDF function q and p |
|
Interval is the main class |
|
distribution free p-box |
|
Functions¶
|
This function casts an array-like structure into an Interval structure. |
Load a NumPy array from a JSON file saved by save_array_to_json(). |
|
|
wildcard scalar interval |
|
|
|
bound the parametric CDF |
|
from parametric distribution specification to define the lower and upper bound of the p-box |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The default p-box constructor for the exponential distribution with scale parameterisation |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
p-box for the lognormal distribution |
|
special case of Uniform distribution as |
Bespoke p-box constructor for the exponential distribution |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Construct a uncertain number given known statistical properties served as constraints. |
|
Equivalent to an interval object constructed as a nonparametric Pbox. |
|
Generates a distribution-free p-box based upon the minimum, maximum and mean of the variable |
|
Nonparametric pbox construction based on constraint of minimum and mean |
|
Generates a distribution-free p-box based upon the minimum, maximum, mean and standard deviation of the variable |
|
Generates a distribution-free p-box based upon the minimum, maximum, mean and standard deviation of the variable |
|
Nonparametric pbox construction based on constraint of mean and var |
|
Generates a distribution-free p-box based upon the minimum, maximum and median of the variable |
|
Nonparametric pbox construction based on constraint of mean and std |
|
Nonparametric pbox construction based on constraint of mean and var |
|
Generates a positive distribution-free p-box based upon the mean and standard deviation of the variable |
|
yields a distribution-free p-box based on specified percentiles of the variable |
|
construct free pbox from sample data by Kolmogorov-Smirnoff confidence bounds |
|
Context manager to temporarily change arithmetic dependency ('f', 'p', 'o', or 'i') |
|
quickly inspect a pbox object |
|
Construct a p-box from two empirical CDF bundles as the extreme bounds |
|
compute the weighted ecdf from (precise) sample data |
|
Convert any input un into a Pbox object |
|
parse an array-like structure into a vector interval |
|
reweight the masses to sum to 1 |
|
compute the weighted ecdf from (precise) sample data |
|
Convert any input un into a Pbox object |
|
calculates the envelope of constructs only |
|
Returns the imposition/intersection of the list of p-boxes |
|
it could work for either Pbox, distribution, DS structure or Intervals |
|
stochastic mixture operation of Intervals with probability masses |
|
|
|
mixture operation for DS structure |
|
nonparametric envelope function directly from data samples |
|
nonparametric envelope function for separate empirical CDFs |
|
bespoke function used for am metric case |
|
bespoke function used for am metric case |
|
construct free pbox from sample data by Kolmogorov-Smirnoff confidence bounds |
Package Contents¶
- class pyuncertainnumber.pba.I(lo: float | numpy.ndarray, hi: float | numpy.ndarray | None = None, do_heavy_checks: bool = True)¶
Bases:
pyuncertainnumber.pba.mixins.NominalValueMixinInterval is the main class
- _lo¶
- _hi = None¶
- run_heavy_checks()¶
Run heavy checks on the interval object
- __repr__()¶
- __str__()¶
- __len__()¶
- __iter__()¶
- __contains__(item)¶
Check if an item is enclosed within the interval.
Example
>>> i = Interval(1,3) >>> 2 in i True >>> 4 in i False
- __next__()¶
- __getitem__(i: int | slice)¶
- to_numpy() numpy.ndarray¶
transform interval objects to numpy arrays
- to_pbox()¶
- lhs_sample(n) numpy.ndarray¶
LHS sampling within the interval
- Parameters:
n – number of samples
- endpoints_lhs_sample(n) numpy.ndarray¶
LHS sampling within the interval plus the endpoints
- Parameters:
n – number of samples
- plot(ax=None, **kwargs)¶
- display()¶
- is_degenerate() bool¶
Check if the interval is degenerate (i.e., has zero width).
- _compute_nominal_value()¶
- ravel()¶
Return a flattened (1D) interval object for multi-dimensional intervals
Example
>>> A = np.random.rand(200, 200, 2) >>> i = pba.intervalise(A) >>> print(i.shape) >>> i2 = i.ravel() >>> print(i2.shape)
- property lo: numpy.ndarray | float¶
- property hi: numpy.ndarray | float¶
- property left¶
- property right¶
- property width¶
- property rad¶
half width
- property mid¶
- property unsized¶
- property val¶
seemingly equivalent to self.to_numpy()
- property scalar¶
Check if the interval is wide sense scalar
Note
wide sense: I(1,2) and I([1],[2]) are both scalars
- property is_scalar¶
Check if the interval is a strict-sense scalar
Note
strict sense: I(1,2) is a scalar, but I([1],[2]) is not
- property shape¶
- property ndim¶
- __neg__()¶
- __pos__()¶
- __add__(other)¶
- __radd__(left)¶
- __sub__(other)¶
- __rsub__(left)¶
- __mul__(other)¶
- __rmul__(left)¶
- __truediv__(other)¶
- __rtruediv__(left)¶
- __pow__(other)¶
- __lt__(other)¶
- __rlt__(left)¶
- __gt__(other)¶
- __rgt__(left)¶
- __le__(other)¶
- __rle__(left)¶
- __ge__(other)¶
- __rge__(left)¶
- __eq__(other)¶
- __ne__(other)¶
- __array_ufunc__(ufunc, method, *inputs, **kwargs)¶
- abs()¶
- sqrt()¶
- exp()¶
- log()¶
- sin()¶
- cos()¶
- tan()¶
- classmethod from_meanform(x, half_width)¶
- save_json(filename: str, comment: str = None, save_dir: str | pathlib.Path = '.') None¶
Save the interval object to a JSON5 file.
- Parameters:
filename (str) – The name of the file (without extension) to save the interval object to.
comment (str, optional) – A comment to include at the top of the file.
save_dir (str | Path, optional) – Directory where the file should be saved. Defaults to current directory.
Note
The file is saved with a .json5 extension.
Example
>>> a.save_json("interval_data", comment="This is interval data", save_dir="results/")
- pyuncertainnumber.pba.intervalise(x_: Any, interval_index=-1) pyuncertainnumber.pba.intervals.number.Interval | Any¶
This function casts an array-like structure into an Interval structure. All array-like structures will be first coerced into an ndarray of floats. If the coercion is unsuccessful the following error is thrown: ValueError: setting an array element with a sequence.
For example this is the expected behaviour: (*) an ndarray of shape (4,2) will be cast as an Interval of shape (4,).
(*) an ndarray of shape (7,3,2) will be cast as an Interval of shape (7,3).
(*) an ndarray of shape (3,2,7) will be cast as a degenerate Interval of shape (3,2,7).
(*) an ndarray of shape (2,3,7) will be cast as an Interval of shape (3,7).
(*) an ndarray of shape (2,3,7,2) will be cast as an Interval of shape (2,3,7) if interval_index is set to -1.
If an ndarray has shape with multiple dimensions having size 2, then the last dimension is intervalised. So, an ndarray of shape (7,2,2) will be cast as an Interval of shape (7,2) with the last dimension intervalised. When the ndarray has shape (2,2) again is the last dimension that gets intervalised.
In case of ambiguity, e.g. (2,5,2), now the first dimension can be forced to be intervalised, selecting index=0, default is -1.
It returns an interval only if the input is an array-like structure, otherwise it returns the following numpy error: ValueError: setting an array element with a sequence.
TODO: Parse a list of mixed numbers: interval and ndarrays.
- pyuncertainnumber.pba.load_interval_from_json(filename: str) pyuncertainnumber.pba.intervals.number.Interval¶
Load a NumPy array from a JSON file saved by save_array_to_json().
Note
Both .json and .json5 files are supported.
Example
>>> interval = load_interval_from_json("interval_data.json5")
- class pyuncertainnumber.pba.Pbox(left: numpy.ndarray | list, right: numpy.ndarray | list, steps=Params.steps, mean=None, var=None, p_values=None)¶
Bases:
pyuncertainnumber.pba.mixins.NominalValueMixin,abc.ABCa base class for Pbox
Danger
this is an abstract class and should not be instantiated directly.
See also
pbox_abc.Staircaseandpbox_abc.Leaffor concrete implementations.- property left¶
- property right¶
- steps = 200¶
- mean = None¶
- var = None¶
- _pvalues¶
- abstractmethod _init_moments()¶
- _init_range()¶
- post_init_check()¶
- steps_check()¶
- _compute_nominal_value()¶
- degenerate_flag() bool¶
check if the pbox is degenerate (i.e. left == right everywhere)
- property degenerate: bool¶
- property p_values¶
- property range¶
- property lo¶
Returns the left-most value in the interval
- property hi¶
Returns the right-most value in the interval
- property support¶
- property median¶
- property enclosed_area¶
the enclosed area between the two extreme cdfs
- __iter__()¶
- __eq__(other)¶
Equality operator for Pbox objects
Note
two pboxes are equal if their left and right bounds are equal
- __contains__(item)¶
- to_interval()¶
discretise pbox into a vec-interval of length of default steps
Note
If desired a custom length of vec-interval as output, use discretise() method.
- to_dss(discretisation=Params.steps)¶
convert pbox to DempsterShafer object
- to_numpy()¶
convert pbox to a 2D numpy array (n, 2) of left and right
- class pyuncertainnumber.pba.Leaf(left=None, right=None, steps=200, mean=None, var=None, dist_params=None, shape=None)¶
Bases:
Staircaseparametric pbox
- shape = None¶
- dist_params = None¶
- _init_moments_range()¶
- __repr__()¶
- sample(n_sam)¶
sample from a parametric pbox or distribution
- class pyuncertainnumber.pba.Params¶
- steps = 200¶
- many = 2000¶
- p_lboundary = 0.001¶
- p_hboundary = 0.999¶
- p_values¶
- scott_hedged_interpretation¶
- user_hedged_interpretation¶
- pyuncertainnumber.pba.wc_scalar_interval(bound)¶
wildcard scalar interval
This function is used to parse a scalar bound into an Interval object. It can handle various input types such as lists, tuples, and strings. If the input is a string, it attempts to interpret it using the hedge_interpret function or parse it as an interval expression. If the input is a single number, it creates an Interval with that number as both bounds.
- pyuncertainnumber.pba.makePbox(func) pyuncertainnumber.pba.pbox_abc.Pbox¶
- pyuncertainnumber.pba._bound_pcdf(dist_family, *args, **kwargs)¶
bound the parametric CDF
Note
top-level implemenatation
only support fully bounded parameters
- pyuncertainnumber.pba._parametric_bounds_array(dist_family, *args, **kwargs)¶
from parametric distribution specification to define the lower and upper bound of the p-box
- Parameters:
dist_family – (str) the name of the distribution
*args – several parameter (interval or list)
**kwargs – scale parameters (interval or list)
Note
middle level implementation
- pyuncertainnumber.pba.norm(*args)¶
- pyuncertainnumber.pba.lognormal(*args)¶
- pyuncertainnumber.pba.alpha(*args)¶
- pyuncertainnumber.pba.anglit(*args)¶
- pyuncertainnumber.pba.argus(*args)¶
- pyuncertainnumber.pba.arcsine(*args)¶
- pyuncertainnumber.pba.beta(*args)¶
- pyuncertainnumber.pba.betaprime(*args)¶
- pyuncertainnumber.pba.bradford(*args)¶
- pyuncertainnumber.pba.burr(*args)¶
- pyuncertainnumber.pba.burr12(*args)¶
- pyuncertainnumber.pba.cauchy(*args)¶
- pyuncertainnumber.pba.chi(*args)¶
- pyuncertainnumber.pba.chi2(*args)¶
- pyuncertainnumber.pba.cosine(*args)¶
- pyuncertainnumber.pba.crystalball(*args)¶
- pyuncertainnumber.pba.dgamma(*args)¶
- pyuncertainnumber.pba.dweibull(*args)¶
- pyuncertainnumber.pba.erlang(*args)¶
- pyuncertainnumber.pba.exponnorm(*args)¶
- pyuncertainnumber.pba.exponential(*args, **kwargs)¶
The default p-box constructor for the exponential distribution with scale parameterisation
Note
scale parameterisation due to scipy.stats. Note that the “scale” argument is a must. There is an “exponential_by_lambda” constructor which uses the rate parameterisation.
Example
>>> pba.pbox_parametric.exponential(scale=[1, 2])
- pyuncertainnumber.pba.exponweib(*args)¶
- pyuncertainnumber.pba.exponpow(*args)¶
- pyuncertainnumber.pba.f(*args)¶
- pyuncertainnumber.pba.fatiguelife(*args)¶
- pyuncertainnumber.pba.fisk(*args)¶
- pyuncertainnumber.pba.foldcauchy(*args)¶
- pyuncertainnumber.pba.foldnorm(mu, s, steps=Params.steps)¶
- pyuncertainnumber.pba.genlogistic(*args)¶
- pyuncertainnumber.pba.gennorm(*args)¶
- pyuncertainnumber.pba.genpareto(*args)¶
- pyuncertainnumber.pba.genexpon(*args)¶
- pyuncertainnumber.pba.genextreme(*args)¶
- pyuncertainnumber.pba.gausshyper(*args)¶
- pyuncertainnumber.pba.gamma(*args)¶
- pyuncertainnumber.pba.gengamma(*args)¶
- pyuncertainnumber.pba.genhalflogistic(*args)¶
- pyuncertainnumber.pba.geninvgauss(*args)¶
- pyuncertainnumber.pba.gompertz(*args)¶
- pyuncertainnumber.pba.gumbel_r(*args)¶
- pyuncertainnumber.pba.gumbel_l(*args)¶
- pyuncertainnumber.pba.halfcauchy(*args)¶
- pyuncertainnumber.pba.halflogistic(*args)¶
- pyuncertainnumber.pba.halfnorm(*args)¶
- pyuncertainnumber.pba.halfgennorm(*args)¶
- pyuncertainnumber.pba.hypsecant(*args)¶
- pyuncertainnumber.pba.invgamma(*args)¶
- pyuncertainnumber.pba.invgauss(*args)¶
- pyuncertainnumber.pba.invweibull(*args)¶
- pyuncertainnumber.pba.irwinhall(*args)¶
- pyuncertainnumber.pba.jf_skew_t(*args)¶
- pyuncertainnumber.pba.johnsonsb(*args)¶
- pyuncertainnumber.pba.johnsonsu(*args)¶
- pyuncertainnumber.pba.kappa4(*args)¶
- pyuncertainnumber.pba.kappa3(*args)¶
- pyuncertainnumber.pba.ksone(*args)¶
- pyuncertainnumber.pba.kstwo(*args)¶
- pyuncertainnumber.pba.kstwobign(*args)¶
- pyuncertainnumber.pba.laplace(*args)¶
- pyuncertainnumber.pba.laplace_asymmetric(*args)¶
- pyuncertainnumber.pba.levy(*args)¶
- pyuncertainnumber.pba.levy_l(*args)¶
- pyuncertainnumber.pba.levy_stable(*args)¶
- pyuncertainnumber.pba.logistic(*args)¶
- pyuncertainnumber.pba.loggamma(*args)¶
- pyuncertainnumber.pba.loglaplace(*args)¶
- pyuncertainnumber.pba.loguniform(*args)¶
- pyuncertainnumber.pba.lomax(*args)¶
- pyuncertainnumber.pba.maxwell(*args)¶
- pyuncertainnumber.pba.mielke(*args)¶
- pyuncertainnumber.pba.moyal(*args)¶
- pyuncertainnumber.pba.nakagami(*args)¶
- pyuncertainnumber.pba.ncx2(*args)¶
- pyuncertainnumber.pba.ncf(*args)¶
- pyuncertainnumber.pba.nct(*args)¶
- pyuncertainnumber.pba.norminvgauss(*args)¶
- pyuncertainnumber.pba.pareto(*args)¶
- pyuncertainnumber.pba.pearson3(*args)¶
- pyuncertainnumber.pba.powerlaw(*args)¶
- pyuncertainnumber.pba.powerlognorm(*args)¶
- pyuncertainnumber.pba.powernorm(*args)¶
- pyuncertainnumber.pba.rdist(*args)¶
- pyuncertainnumber.pba.rayleigh(*args, **kwargs)¶
- pyuncertainnumber.pba.rel_breitwigner(*args)¶
- pyuncertainnumber.pba.rice(*args)¶
- pyuncertainnumber.pba.recipinvgauss(*args)¶
- pyuncertainnumber.pba.semicircular(*args)¶
- pyuncertainnumber.pba.skewcauchy(*args)¶
- pyuncertainnumber.pba.skewnorm(*args)¶
- pyuncertainnumber.pba.studentized_range(*args)¶
- pyuncertainnumber.pba.t(*args)¶
- pyuncertainnumber.pba.trapezoid(*args)¶
- pyuncertainnumber.pba.triang(*args)¶
- pyuncertainnumber.pba.truncweibull_min(*args)¶
- pyuncertainnumber.pba.tukeylambda(*args)¶
- pyuncertainnumber.pba.uniform_sps(*args)¶
- pyuncertainnumber.pba.vonmises(*args)¶
- pyuncertainnumber.pba.vonmises_line(*args)¶
- pyuncertainnumber.pba.wald(*args)¶
- pyuncertainnumber.pba.weibull_min(*args)¶
- pyuncertainnumber.pba.weibull_max(*args)¶
- pyuncertainnumber.pba.wrapcauchy(*args)¶
- pyuncertainnumber.pba.lognormal_weird(mean, var, steps=Params.steps)¶
p-box for the lognormal distribution
*Note: the parameters used are the mean and variance of the lognormal distribution
not the mean and variance of the underlying normal* See: [1]<https://en.wikipedia.org/wiki/Log-normal_distribution#Generation_and_parameters> [2]<https://stackoverflow.com/questions/51906063/distribution-mean-and-standard-deviation-using-scipy-stats>
- Parameters:
mean – mean of the lognormal distribution
var – variance of the lognormal distribution
- Return type:
- pyuncertainnumber.pba.uniform(a, b, steps=Params.steps)¶
special case of Uniform distribution as Scipy has an unbelivably strange parameterisation than common sense
- Parameters:
a (-) – (float) lower endpoint
b (-) – (float) upper endpoints
- pyuncertainnumber.pba.exponential_by_lambda(lamb: list | pyuncertainnumber.pba.intervals.number.Interval) pyuncertainnumber.pba.pbox_abc.Pbox¶
Bespoke p-box constructor for the exponential distribution
- Parameters:
lamb (-) – (list or Interval) the rate parameter of the exponential distribution
- pyuncertainnumber.pba.trapz(a, b, c, d, steps=Params.steps)¶
- pyuncertainnumber.pba.weibull(*args, steps=Params.steps)¶
- pyuncertainnumber.pba.KM(k, m, steps=Params.steps)¶
- pyuncertainnumber.pba.KN(k, n, steps=Params.steps)¶
- pyuncertainnumber.pba.bernoulli(*args)¶
- pyuncertainnumber.pba.betabinom(*args)¶
- pyuncertainnumber.pba.betanbinom(*args)¶
- pyuncertainnumber.pba.binom(*args)¶
- pyuncertainnumber.pba.boltzmann(*args)¶
- pyuncertainnumber.pba.dlaplace(*args)¶
- pyuncertainnumber.pba.geom(*args)¶
- pyuncertainnumber.pba.hypergeom(*args)¶
- pyuncertainnumber.pba.logser(*args)¶
- pyuncertainnumber.pba.nbinom(*args)¶
- pyuncertainnumber.pba.nchypergeom_fisher(*args)¶
- pyuncertainnumber.pba.nchypergeom_wallenius(*args)¶
- pyuncertainnumber.pba.nhypergeom(*args)¶
- pyuncertainnumber.pba.planck(*args)¶
- pyuncertainnumber.pba.poisson(*args)¶
- pyuncertainnumber.pba.randint(*args)¶
- pyuncertainnumber.pba.skellam(*args)¶
- pyuncertainnumber.pba.yulesimon(*args)¶
- pyuncertainnumber.pba.zipf(*args)¶
- pyuncertainnumber.pba.zipfian(*args)¶
- pyuncertainnumber.pba.normal¶
- pyuncertainnumber.pba.gaussian¶
- pyuncertainnumber.pba.named_pbox¶
- pyuncertainnumber.pba.known_properties(maximum=None, mean=None, median=None, minimum=None, mode=None, percentiles=None, std=None, var=None, family=None, **kwargs) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber¶
Construct a uncertain number given known statistical properties served as constraints.
- Parameters:
maximum (number) – maximum value of the variable
mean (number) – mean value of the variable
median (number) – median value of the variable
minimum (number) – minimum value of the variable
mode (number) – mode value of the variable
percentiles (dict) – dictionary of percentiles and their values, e.g. {0: 0, 0.1: 1, 0.5: 2, 0.9: pun.I(3,4), 1:5}
std (number) – standard deviation of the variable
var (number) – variance of the variable
family (str) – name of the distribution family, e.g. ‘normal’, ‘lognormal’, ‘uniform’, ‘triangular’, etc.
- Returns:
uncertain number
Note
It’s also possible to directly call a function given the known information, such as
pun.mean_std(mean=1, std=0.5).Example
>>> from pyuncertainnumber.pba import known_properties >>> known_properties( ... maximum = 2, ... mean = 1, ... var = 0.25, ... minimum=0, ... )
- pyuncertainnumber.pba.known_constraints¶
- pyuncertainnumber.pba.min_max(minimum: numbers.Number, maximum: numbers.Number) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Equivalent to an interval object constructed as a nonparametric Pbox.
- Parameters:
minimum – Left end of box
maximum – Right end of box
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> from pyuncertainnumber.pba import min_max >>> min_max(0, 2) # return a UncertainNumber >>> min_max(0, 2, return_construct=True) # return a Pbox
- pyuncertainnumber.pba.min_max_mean(minimum: numbers.Number, maximum: numbers.Number, mean: numbers.Number, steps: int = Params.steps) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Generates a distribution-free p-box based upon the minimum, maximum and mean of the variable
- Parameters:
minimum (float) – minimum value of the variable
maximum (float) – maximum value of the variable
mean (float) – mean value of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> min_max_mean(0, 2, 1)
- pyuncertainnumber.pba.min_mean(minimum, mean, steps=Params.steps) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Nonparametric pbox construction based on constraint of minimum and mean
- Parameters:
minimum (number) – minimum value of the variable
mean (number) – mean value of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> from pyuncertainnumber.pba import min_mean >>> min_mean(0, 1) # return a UncertainNumber >>> min_mean(0, 1, return_construct=True) # return a Pbox
- pyuncertainnumber.pba.min_max_mean_std(minimum: numbers.Number, maximum: numbers.Number, mean: numbers.Number, std: numbers.Number, **kwargs) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Generates a distribution-free p-box based upon the minimum, maximum, mean and standard deviation of the variable
- Parameters:
maximum (number) – maximum value of the variable
minimum (number) – minimum value of the variable
std (number) – standard deviation of the variable
var (number) – variance of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> min_max_mean_std(0, 2, 1, 0.5) # return a UncertainNumber
See also
- pyuncertainnumber.pba.min_max_mean_var(minimum: numbers.Number, maximum: numbers.Number, mean: numbers.Number, var: numbers.Number, **kwargs) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Generates a distribution-free p-box based upon the minimum, maximum, mean and standard deviation of the variable
- Parameters:
minimum (number) – minimum value of the variable
maximum (number) – maximum value of the variable
mean (number) – mean value of the variable
var (number) – variance of the variable
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> min_max_mean_var(0, 2, 1, 0.25) # return a UncertainNumber
Implementation
Equivalent to
min_max_mean_std(minimum,maximum,mean,np.sqrt(var))See also
- pyuncertainnumber.pba.min_max_mode(minimum: numbers.Number, maximum: numbers.Number, mode: numbers.Number, steps: int = Params.steps) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Nonparametric pbox construction based on constraint of mean and var
- Parameters:
minimum – minimum value of the variable
maximum – maximum value of the variable
mode (number) – mode value of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> min_max_mode(0, 2, 1) # return a UncertainNumber
- pyuncertainnumber.pba.min_max_median(minimum: numbers.Number, maximum: numbers.Number, median: numbers.Number, steps: int = Params.steps) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Generates a distribution-free p-box based upon the minimum, maximum and median of the variable
- Parameters:
minimum – minimum value of the variable
maximum – maximum value of the variable
median – median value of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> min_max_median(0, 2, 1) # return a UncertainNumber
- pyuncertainnumber.pba.mean_std(mean: numbers.Number, std: numbers.Number, steps=Params.steps) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Nonparametric pbox construction based on constraint of mean and std
- Parameters:
mean (number) – mean value of the variable
std (number) – std value of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> mean_std(1, 0.5)
- pyuncertainnumber.pba.mean_var(mean: numbers.Number, var: numbers.Number) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
Nonparametric pbox construction based on constraint of mean and var
- Parameters:
mean (number) – mean value of the variable
vasr (number) – var value of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> mean_var(1, 0.25) # return a UncertainNumber
- pyuncertainnumber.pba.pos_mean_std(mean: numbers.Number, std: numbers.Number, steps=Params.steps) pyuncertainnumber.pba.pbox_abc.Pbox¶
Generates a positive distribution-free p-box based upon the mean and standard deviation of the variable
- Parameters:
mean – mean of the variable
std – standard deviation of the variable
- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
- pyuncertainnumber.pba.from_percentiles(percentiles: dict, steps: int = Params.steps) pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber | pyuncertainnumber.pba.pbox_abc.Pbox¶
yields a distribution-free p-box based on specified percentiles of the variable
- Parameters:
percentiles – dictionary of percentiles and their values (e.g. {0: 0, 0.1: 1, 0.5: 2, 0.9: I(3,4), 1:5})
steps – number of steps to use in the p-box
Note
The percentiles dictionary is of the form {percentile: value}. Where value can either be a number or an I. If value is a number, the percentile is assumed to be a point percentile. If value is an I, the percentile is assumed to be an interval percentile. If no keys for 0 and 1 are given,
-np.infandnp.infare used respectively. This will result in a p-box that is not bounded and raise a warning. If the percentiles are not increasing, the percentiles will be intersected. This may not be desired behaviour. ValueError: If any of the percentiles are not between 0 and 1.- Returns:
UncertainNumber or Pbox
Tip
Two types of return values are possible:
by default, a UncertainNumber is returned;
For low-level controls, if return_construct=True is specified, a Pbox is returned.
Example
>>> pba.from_percentiles( >>> {0: 0, >>> 0.25: 0.5, >>> 0.5: pba.I(1,2), >>> 0.75: pba.I(1.5,2.5), >>> 1: 3}) >>> .display()
- pyuncertainnumber.pba.KS_bounds(s: numpy.typing.ArrayLike, alpha: float, display=True, output_type='bounds') tuple[pyuncertainnumber.pba.ecdf.eCDF_bundle] | pyuncertainnumber.pba.pbox_abc.Pbox | pyuncertainnumber.UncertainNumber¶
construct free pbox from sample data by Kolmogorov-Smirnoff confidence bounds
- Parameters:
s (ArrayLike) – sample data, precise and imprecise
dn (float) – KS critical value at a significance level and sample size N;
output_type (str) – A choice between {‘bounds’, ‘pbox’, ‘un’}, default=’bounds’ which returns two eCDF bundles as bounds; ‘pbox’ to return a pbox object; ‘un’ to return an uncertain number object.
- Returns:
a tuple of two CDF bounds, i.e. upper and lower (eCDF_bundle objects), or a Pbox object, or an UncertainNumber object the return type is controlled by the output_type argument.
Note
By default the function returns two eCDF bundles as the extreme bounds. With the upper and lower bounds, a free pbox can be constructed.
Example
>>> # both precise data (e.g. numpy array) and imprecise data (e.g. a vector of interval) are supported >>> precise_data = np.random.normal(0, 1, 100) # precise data case >>> ub, lb = pba.KS_bounds(precise_data, alpha=0.025, display=True)
>>> # alternatively, an uncertain number or a p-box can be returned >>> pba.KS_bounds(precise_data, alpha=0.025, display=False, output_type='pbox') # return a pbox object >>> pba.KS_bounds(precise_data, alpha=0.025, display=False, output_type='un') # return an uncertain number object
>>> # imprecise data case >>> impre_data = pba.I(lo = precise_data -0.5, hi = precise_data + 0.5) >>> ub, lb = pba.KS_bounds(impre_data, alpha=0.025, display=True)
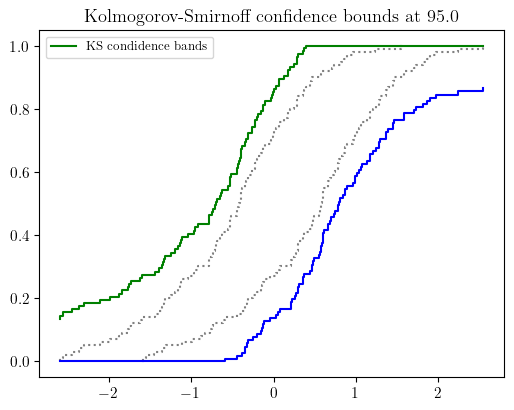
Kolmogorov-Smirnoff confidence bounds illustration with precise and imprecise data.¶
- class pyuncertainnumber.pba.DempsterShafer(intervals: pyuncertainnumber.pba.intervals.Interval | list[list] | list[pyuncertainnumber.pba.intervals.Interval] | numpy.ndarray, masses: numpy.typing.ArrayLike)¶
Bases:
pyuncertainnumber.pba.mixins.NominalValueMixin,pyuncertainnumber.pba.mixins._PboxOpsMixinClass for Dempester-Shafer structures.
- Parameters:
intervals – expect wildcard vector intervals, vec-Interval; list of scalar intervals; list of list pairs; or 2D array;
masses (ArrayLike) – probability masses
Example
>>> from pyuncertainnumber import pba >>> dss = pba.DempsterShafer(intervals=[[1,5], [3,6]], masses=[0.5, 0.5]) >>> dss.structures [dempstershafer_element(interval=[1.0,5.0], mass=0.5), dempstershafer_element(interval=[3.0,6.0], mass=0.5)]
Note
Dempster-Shafer structures are also called belief structures or evidence structures, and it can be converted to p-boxes.
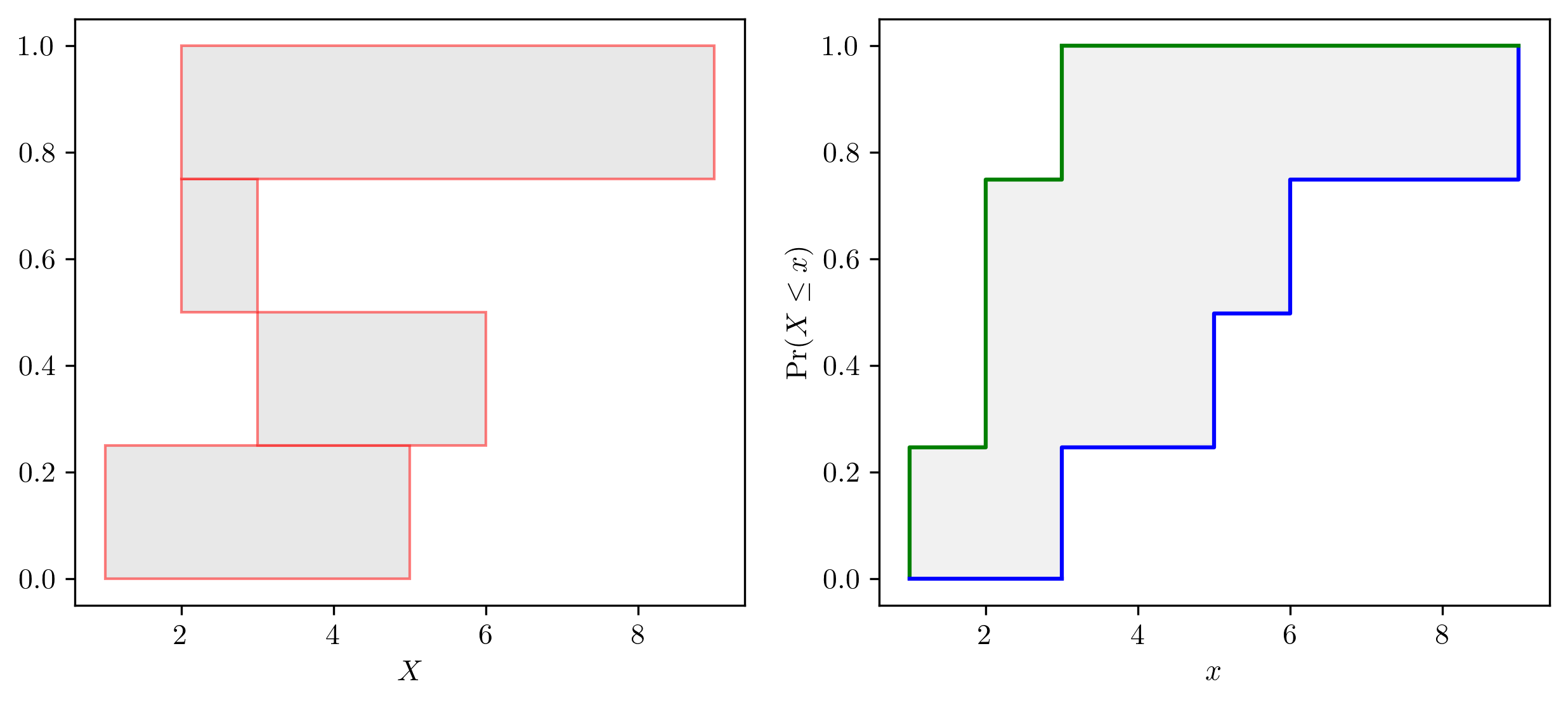
P-box and Dempster Shafer structure illustration.¶
- _intervals¶
- _masses¶
- _create_DSstructure()¶
- __repr__()¶
- _compute_nominal_value()¶
- property structures¶
- property intervals¶
Returns the Interval-typed focal elements of the Dempster-Shafer structure.
- property focal_elements¶
Returns the focal elements of the Dempster-Shafer structure.
- property masses¶
- plot(style='raw', ax=None, zorder=None, **kwargs)¶
for box type transform dss into a pbox and plot
- Parameters:
style (str) – “raw” (default), “box”, “pbox”, “interval”
edge_color (str) – edge color for raw style. If None, use default red color.
- display(style='box', ax=None, **kwargs)¶
- to_pbox()¶
- _to_pbox()¶
for mixin use only
- classmethod from_dsElements(*ds_elements: dempstershafer_element)¶
Create a Dempster-Shafer structure from a list of Dempster-Shafer elements.
- class pyuncertainnumber.pba.DSS(intervals: pyuncertainnumber.pba.intervals.Interval | list[list] | list[pyuncertainnumber.pba.intervals.Interval] | numpy.ndarray, masses: numpy.typing.ArrayLike)¶
Bases:
pyuncertainnumber.pba.mixins.NominalValueMixin,pyuncertainnumber.pba.mixins._PboxOpsMixinClass for Dempester-Shafer structures.
- Parameters:
intervals – expect wildcard vector intervals, vec-Interval; list of scalar intervals; list of list pairs; or 2D array;
masses (ArrayLike) – probability masses
Example
>>> from pyuncertainnumber import pba >>> dss = pba.DempsterShafer(intervals=[[1,5], [3,6]], masses=[0.5, 0.5]) >>> dss.structures [dempstershafer_element(interval=[1.0,5.0], mass=0.5), dempstershafer_element(interval=[3.0,6.0], mass=0.5)]
Note
Dempster-Shafer structures are also called belief structures or evidence structures, and it can be converted to p-boxes.
P-box and Dempster Shafer structure illustration.¶
- _intervals¶
- _masses¶
- _create_DSstructure()¶
- __repr__()¶
- _compute_nominal_value()¶
- property structures¶
- property intervals¶
Returns the Interval-typed focal elements of the Dempster-Shafer structure.
- property focal_elements¶
Returns the focal elements of the Dempster-Shafer structure.
- property masses¶
- plot(style='raw', ax=None, zorder=None, **kwargs)¶
for box type transform dss into a pbox and plot
- Parameters:
style (str) – “raw” (default), “box”, “pbox”, “interval”
edge_color (str) – edge color for raw style. If None, use default red color.
- display(style='box', ax=None, **kwargs)¶
- to_pbox()¶
- _to_pbox()¶
for mixin use only
- classmethod from_dsElements(*ds_elements: dempstershafer_element)¶
Create a Dempster-Shafer structure from a list of Dempster-Shafer elements.
- class pyuncertainnumber.pba.D¶
Bases:
pyuncertainnumber.pba.mixins.NominalValueMixinTwo signatures are currentlly supported, either a parametric specification or from a nonparametric empirical data set.
Note
the nonparametric instasntiation via arrtribute empirical_data will be deprecated soon. We have introduced a
distributions.ECDFclass instead.Example
>>> d = Distribution('gaussian', (0,1))
- dist_family: str = None¶
- dist_params: list[float] | tuple[float, Ellipsis] = None¶
- empirical_data: list[float] | numpy.ndarray = None¶
- skip_post: bool = False¶
- __post_init__()¶
- __repr__()¶
- rep()¶
Create the underling dist object either sps dist or sample approximated or pbox dist
Note
underlying constructor to create the scipy.stats distribution object
- _match_distribution()¶
match the distribution object based on the family and parameters
- parse_params_from_dist()¶
- flag()¶
boolean flag for if the distribution is a parameterised distribution or not .. note:
- only parameterised dist can do sampling - for non-parameterised sample-data based dist, next steps could be fitting
- sample(size)¶
generate deviates from the distribution
- generate_rns(N)¶
generate ‘N’ random numbers from the distribution
- alpha_cut(alpha)¶
alpha cut interface
- make_nominal_value()¶
one value representation of the distribution .. note:: - use mean for now;
- plot(**kwargs)¶
display the distribution
- display(**kwargs)¶
- _get_hint()¶
- fit(data)¶
fit the distribution to the data
- get_PI(alpha: numbers.Number = 0.95) pyuncertainnumber.Interval¶
Compute the predictive interval at the coverage level of alpha
- Parameters:
alpha (-) – coverage level, default is 0.95
Example
>>> from pyuncertainnumber import pba >>> d = pba.Distribution('gaussian', (0, 1)) >>> pi = d.get_PI(alpha=0.95) >>> print(pi) # prints the interval at the 95% coverage level
- pdf(x: numpy.typing.ArrayLike)¶
compute the probability density function (pdf) at x
- log_pdf_eval(x: numpy.typing.ArrayLike)¶
compute the log of probability density function (pdf) at x
- cdf(x: numpy.typing.ArrayLike)¶
compute the cumulative distribution function (cdf) at x
- get_whole_cdf()¶
return the cumulative distribution function (cdf)
- _compute_nominal_value()¶
- property dist¶
the underlying sps.dist object
- property lo¶
- property hi¶
- property range¶
- property hint¶
- classmethod dist_from_sps(dist: scipy.stats.rv_continuous | scipy.stats.rv_discrete, shape: str = None)¶
- to_pbox()¶
convert the distribution to a pbox .. note:
- this only works for parameteried distributions for now - later on work with sample-approximated dist until `fit()`is implemented
- __neg__()¶
- __add__(other)¶
- __radd__(other)¶
- __sub__(other)¶
- __rsub__(other)¶
- __mul__(other)¶
- __rmul__(other)¶
- __truediv__(other)¶
- __rtruediv__(other)¶
- __pow__(other)¶
- __rpow__(other)¶
- class pyuncertainnumber.pba.Distribution¶
Bases:
pyuncertainnumber.pba.mixins.NominalValueMixinTwo signatures are currentlly supported, either a parametric specification or from a nonparametric empirical data set.
Note
the nonparametric instasntiation via arrtribute empirical_data will be deprecated soon. We have introduced a
distributions.ECDFclass instead.Example
>>> d = Distribution('gaussian', (0,1))
- dist_family: str = None¶
- dist_params: list[float] | tuple[float, Ellipsis] = None¶
- empirical_data: list[float] | numpy.ndarray = None¶
- skip_post: bool = False¶
- __post_init__()¶
- __repr__()¶
- rep()¶
Create the underling dist object either sps dist or sample approximated or pbox dist
Note
underlying constructor to create the scipy.stats distribution object
- _match_distribution()¶
match the distribution object based on the family and parameters
- parse_params_from_dist()¶
- flag()¶
boolean flag for if the distribution is a parameterised distribution or not .. note:
- only parameterised dist can do sampling - for non-parameterised sample-data based dist, next steps could be fitting
- sample(size)¶
generate deviates from the distribution
- generate_rns(N)¶
generate ‘N’ random numbers from the distribution
- alpha_cut(alpha)¶
alpha cut interface
- make_nominal_value()¶
one value representation of the distribution .. note:: - use mean for now;
- plot(**kwargs)¶
display the distribution
- display(**kwargs)¶
- _get_hint()¶
- fit(data)¶
fit the distribution to the data
- get_PI(alpha: numbers.Number = 0.95) pyuncertainnumber.Interval¶
Compute the predictive interval at the coverage level of alpha
- Parameters:
alpha (-) – coverage level, default is 0.95
Example
>>> from pyuncertainnumber import pba >>> d = pba.Distribution('gaussian', (0, 1)) >>> pi = d.get_PI(alpha=0.95) >>> print(pi) # prints the interval at the 95% coverage level
- pdf(x: numpy.typing.ArrayLike)¶
compute the probability density function (pdf) at x
- log_pdf_eval(x: numpy.typing.ArrayLike)¶
compute the log of probability density function (pdf) at x
- cdf(x: numpy.typing.ArrayLike)¶
compute the cumulative distribution function (cdf) at x
- get_whole_cdf()¶
return the cumulative distribution function (cdf)
- _compute_nominal_value()¶
- property dist¶
the underlying sps.dist object
- property lo¶
- property hi¶
- property range¶
- property hint¶
- classmethod dist_from_sps(dist: scipy.stats.rv_continuous | scipy.stats.rv_discrete, shape: str = None)¶
- to_pbox()¶
convert the distribution to a pbox .. note:
- this only works for parameteried distributions for now - later on work with sample-approximated dist until `fit()`is implemented
- __neg__()¶
- __add__(other)¶
- __radd__(other)¶
- __sub__(other)¶
- __rsub__(other)¶
- __mul__(other)¶
- __rmul__(other)¶
- __truediv__(other)¶
- __rtruediv__(other)¶
- __pow__(other)¶
- __rpow__(other)¶
- class pyuncertainnumber.pba.JointDistribution(copula: pyuncertainnumber.pba.dependency.Dependency, marginals: list[Distribution])¶
Joint distribution class
Example
>>> from pyuncertainnumber import pba >>> dist_a, dist_b = pba.Distribution('gaussian', (5,1)), pba.Distribution('uniform', (2, 3)) >>> c = pba.Dependency('gaussian', params=0.8) >>> joint_dist = pba.JointDistribution(copula=c, marginals=[dist_a, dist_b]) >>> samples = joint_dist.sample(size=1000)
- marginals¶
- copula¶
- _joint_dist¶
- ndim¶
- __repr__()¶
- static from_sps(copula: statsmodels.distributions.copula, marginals: list[scipy.stats.rv_continuous])¶
- sample(size, random_state=42)¶
generate orginal-space samples from the joint distribution
- u_sample(size, random_state=42)¶
generate copula-space samples from the joint distribution
- joint_density_of_bi_grid(x: numpy.typing.ArrayLike, y: numpy.typing.ArrayLike)¶
compute the joint density on a grid given x and y arrays
Used for bivariate arithmetic calculations of X and Y with designated (known) dependency and marginals.
Note
discretisation step sizes dx and dy are set up by the input x and y arrays
Example
>>> x = np.linspace(0, 1, 50) >>> y = np.linspace(0, 1, 50) >>> dep = Dependency("gaussian", params=0.7) >>> joint_density = dep.joint_density_of_grid(x, y)
- static cdf_of_g(XX, YY, fXY, dx, dy, g_func, z_vals) numpy.typing.ArrayLike¶
Numerically approximate F_Z(z) = P(g(X,Y) <= z) via discretisation on a grid
- Parameters:
z_vals (ArrayLike) – discretisation of z values (array) at which to compute F_Z
XX – the grid arrays from meshgrid
YY – the grid arrays from meshgrid
fXY – joint density on the grid
dx – spacings in x and y directions
dy – spacings in x and y directions
g_func (callable) – a general callable applied elementwise to (XX, YY)
- Returns:
cumulative distribution function values at z_vals
- Return type:
FZ (ArrayLike)
Note
given precomputed grid (XX,YY), joint density fXY, and spacings.
- class pyuncertainnumber.pba.ECDF(empirical_data: numpy.ndarray)¶
Bases:
pyuncertainnumber.pba.pbox_abc.StaircaseEmpirical cumulative distribution function (ecdf) class
Implementation
supported by Pbox API hence samples will be degenerate intervals
Example
>>> import numpy as np >>> s = np.random.normal(size=1000) >>> ecdf = ECDF(s) >>> ecdf.plot()
- class pyuncertainnumber.pba.Dependency(family: str, params: numbers.Number | None = None, **kwargs)¶
Dependency class to specify copula models.
- Parameters:
family (str) – Name of the copula family, one of “gaussian”, “t”, “frank”, “gumbel”, “clayton”, “independence”.
params (Number | None) – Backward-compatible single-parameter shortcut: - gaussian/t: interpreted as corr - frank/gumbel/clayton: interpreted as theta - independence: ignored
**kwargs – Any keyword parameters supported by the selected copula, e.g. corr=…, df=…, theta=…, k_dim=…, allow_singular=…
Examples
>>> Dependency("gaussian", params=0.8, k_dim=3) # legacy style >>> Dependency("gaussian", corr=0.8, k_dim=3) # explicit >>> Dependency("t", corr=0.6, df=5, k_dim=4) >>> Dependency("frank", theta=2.5, k_dim=2) >>> Dependency("independence", k_dim=5)
- copulas_dict¶
- _single_param_alias¶
- family = ''¶
- params = None¶
- _copula¶
- property copula¶
Access the underlying statsmodels copula instance.
- _post_init_check()¶
- __repr__()¶
- pdf(u)¶
- cdf(u)¶
- u_sample(n: int, random_state=None)¶
draws n samples in the U space (unit hypercube)
- display(style='3d_cdf', ax=None)¶
show the PDF or CDF in the u space
- fit(data)¶
- pyuncertainnumber.pba.dependency(dep_type: str)¶
Context manager to temporarily change arithmetic dependency (‘f’, ‘p’, ‘o’, or ‘i’)
- pyuncertainnumber.pba.inspect_pbox(pbox)¶
quickly inspect a pbox object
- pyuncertainnumber.pba.pbox_from_ecdf_bundle(lower_bound: pyuncertainnumber.pba.ecdf.eCDF_bundle, upper_bound: pyuncertainnumber.pba.ecdf.eCDF_bundle) Pbox¶
Construct a p-box from two empirical CDF bundles as the extreme bounds
- pyuncertainnumber.pba.get_ecdf(s, w=None, display=False) tuple¶
compute the weighted ecdf from (precise) sample data
- Parameters:
s (array-like) – 1 dimensional precise sample data
w (array-like) – weights
Note
Sudret eq.1
- Returns:
ecdf in the form of a tuple of q and p
- pyuncertainnumber.pba.convert(un)¶
Convert any input un into a Pbox object
Note
theorically ‘un’ can be {Interval, DempsterShafer, Distribution, float, int}
- pyuncertainnumber.pba.make_vec_interval(vec)¶
parse an array-like structure into a vector interval
For most part, it works same to intervalise, except that this function can also handle a list of UN objects.
Example
>>> a, b = pba.I(1, 2), pba.I(3, 4) >>> make_vec_interval([a, b]) Interval([1, 3], [2, 4])
- pyuncertainnumber.pba.reweighting(*masses)¶
reweight the masses to sum to 1
- class pyuncertainnumber.pba.eCDF_bundle¶
a handy tuple of eCDF function q and p
- quantiles: numpy.ndarray¶
- probabilities: numpy.ndarray¶
- __repr__()¶
- classmethod from_sps_ecdf(e)¶
utility to tranform sps.ecdf to eCDF_bundle
- plot_bounds(other)¶
plot the lower and upper bounds
- pyuncertainnumber.pba.get_ecdf(s, w=None, display=False) tuple¶
compute the weighted ecdf from (precise) sample data
- Parameters:
s (array-like) – 1 dimensional precise sample data
w (array-like) – weights
Note
Sudret eq.1
- Returns:
ecdf in the form of a tuple of q and p
- class pyuncertainnumber.pba.Interval(lo: float | numpy.ndarray, hi: float | numpy.ndarray | None = None, do_heavy_checks: bool = True)¶
Bases:
pyuncertainnumber.pba.mixins.NominalValueMixinInterval is the main class
- _lo¶
- _hi = None¶
- run_heavy_checks()¶
Run heavy checks on the interval object
- __repr__()¶
- __str__()¶
- __len__()¶
- __iter__()¶
- __contains__(item)¶
Check if an item is enclosed within the interval.
Example
>>> i = Interval(1,3) >>> 2 in i True >>> 4 in i False
- __next__()¶
- __getitem__(i: int | slice)¶
- to_numpy() numpy.ndarray¶
transform interval objects to numpy arrays
- to_pbox()¶
- lhs_sample(n) numpy.ndarray¶
LHS sampling within the interval
- Parameters:
n – number of samples
- endpoints_lhs_sample(n) numpy.ndarray¶
LHS sampling within the interval plus the endpoints
- Parameters:
n – number of samples
- plot(ax=None, **kwargs)¶
- display()¶
- is_degenerate() bool¶
Check if the interval is degenerate (i.e., has zero width).
- _compute_nominal_value()¶
- ravel()¶
Return a flattened (1D) interval object for multi-dimensional intervals
Example
>>> A = np.random.rand(200, 200, 2) >>> i = pba.intervalise(A) >>> print(i.shape) >>> i2 = i.ravel() >>> print(i2.shape)
- property lo: numpy.ndarray | float¶
- property hi: numpy.ndarray | float¶
- property left¶
- property right¶
- property width¶
- property rad¶
half width
- property mid¶
- property unsized¶
- property val¶
seemingly equivalent to self.to_numpy()
- property scalar¶
Check if the interval is wide sense scalar
Note
wide sense: I(1,2) and I([1],[2]) are both scalars
- property is_scalar¶
Check if the interval is a strict-sense scalar
Note
strict sense: I(1,2) is a scalar, but I([1],[2]) is not
- property shape¶
- property ndim¶
- __neg__()¶
- __pos__()¶
- __add__(other)¶
- __radd__(left)¶
- __sub__(other)¶
- __rsub__(left)¶
- __mul__(other)¶
- __rmul__(left)¶
- __truediv__(other)¶
- __rtruediv__(left)¶
- __pow__(other)¶
- __lt__(other)¶
- __rlt__(left)¶
- __gt__(other)¶
- __rgt__(left)¶
- __le__(other)¶
- __rle__(left)¶
- __ge__(other)¶
- __rge__(left)¶
- __eq__(other)¶
- __ne__(other)¶
- __array_ufunc__(ufunc, method, *inputs, **kwargs)¶
- abs()¶
- sqrt()¶
- exp()¶
- log()¶
- sin()¶
- cos()¶
- tan()¶
- classmethod from_meanform(x, half_width)¶
- save_json(filename: str, comment: str = None, save_dir: str | pathlib.Path = '.') None¶
Save the interval object to a JSON5 file.
- Parameters:
filename (str) – The name of the file (without extension) to save the interval object to.
comment (str, optional) – A comment to include at the top of the file.
save_dir (str | Path, optional) – Directory where the file should be saved. Defaults to current directory.
Note
The file is saved with a .json5 extension.
Example
>>> a.save_json("interval_data", comment="This is interval data", save_dir="results/")
- class pyuncertainnumber.pba.Staircase(left, right, steps=200, mean=None, var=None, p_values=None)¶
Bases:
Pboxdistribution free p-box
- _init_moments()¶
Initialize mean/var interval estimates.
- strategy:
Try LP-based bounds.
If that fails, try ECDF-based bounds.
If that also fails, set to NaN intervals so the program continues.
This function NEVER raises.
- __repr__()¶
- plot(title=None, ax=None, style='box', fill_color='lightgray', bound_colors=None, bound_styles=None, left_line_kwargs=None, right_line_kwargs=None, nuance='step', alpha=0.3, **kwargs)¶
default plotting function
- Parameters:
style (str) – ‘box’ or ‘simple’
fill_color (str) – color to fill the box (only for ‘box’ style)
bound_colors (list) – list of two colors for left and right bound lines
bound_styles (list) – list of two linestyles for left and right bound lines
left_line_kwargs (dict) – additional kwargs for left bound line
right_line_kwargs (dict) – additional kwargs for right bound line
nuance (str) – ‘step’ or ‘curve’ for bound line styles
alpha (float) – transparency level for the box fill (only for ‘box’ style)
**kwargs – additional keyword arguments for the plot
Note
Two styles are supported: a ‘box’ with fill-in color and a ‘simple’ one without fill-in color. Color and linestyle of the bound lines can be customized via the bound_styles, left_line_kwargs, and right_line_kwargs parameters. The argument nuance controls whether the bound lines are plotted as step functions (‘step’) or smooth curves (‘curve’).
Example
>>> a = pba.normal([2, 6], [0.5, 1]) >>> fig, ax = plt.subplots() >>> a.plot(ax=ax, style='simple') # simple style without fill-in color >>> # box style with fill-in color and also customized bound colors >>> a.plot(ax=ax, style='box', ... fill_color='lightblue', ... bound_colors = ['lightblue', 'lightblue'], ... bound_styles=("--", ":"), ... alpha=0.5 ... ) >>> # customized left and right bound line styles >>> ax = pbox.plot( ... left_line_kwargs={"linestyle": "--", "linewidth": 2}, ... right_line_kwargs={"linestyle": ":", "linewidth": 2, "alpha": 0.8}, )
- plot_reverse_axis(title=None, ax=None, style='box', fill_color='lightgray', bound_colors=None, nuance='step', alpha=0.3, orientation='xy', invert_xaxis=True, **kwargs)¶
A testing plotting function that can swap quantile and probability axes.
- Parameters:
style (str) – ‘box’ or ‘simple’
orientation (str) – ‘xy’ keeps x on horizontal and Pr(X<=x) on vertical; ‘yx’ swaps them.
- plot_outside_legend(title=None, ax=None, style='box', fill_color='lightgray', bound_colors=None, nuance='step', alpha=0.3, **kwargs)¶
a specific variant of plot() which is used for scipy proceeding only.
- Parameters:
style (str) – ‘box’ or ‘simple’
- display(*args, **kwargs)¶
- plot_probability_bound(x: float, ax=None, linecolor='r', markercolor='r', **kwargs)¶
plot the probability bound at a certain quantile x
Note
a vertical line
- plot_quantile_bound(p: float, ax=None, **kwargs)¶
plot the quantile bound at a certain probability level p
Note
a horizontal line
- classmethod from_CDFbundle(a, b)¶
pbox from two emipirical CDF bundle
- Parameters:
a (-) – CDF bundle of lower extreme F;
b (-) – CDF bundle of upper extreme F;
- __neg__()¶
- __add__(other)¶
- __radd__(other)¶
- __sub__(other)¶
- __rsub__(other)¶
- __mul__(other)¶
- __rmul__(other)¶
- __truediv__(other)¶
- __rtruediv__(other)¶
- __pow__(other)¶
- __rpow__(other: numbers.Number)¶
Power operation with the base as other and self as the exponent
- __array_ufunc__(ufunc, method, *inputs, **kwargs)¶
- cdf(x: numpy.ndarray)¶
get the bounds on the cdf w.r.t x value
- Parameters:
x (array-like) – x values
- alpha_cut(alpha=0.5)¶
test the lightweight alpha_cut method
- Parameters:
alpha (array-like) – probability levels
- sample(n_sam)¶
LHS sampling by default
- precise_sample(n_a: int, theta: float = None, n_e: int = None)¶
Generate precise samples from a p-box
- discretise(n=None) pyuncertainnumber.Interval¶
alpha-cut discretisation of the p-box without outward rounding
- Parameters:
n (int) – number of steps to be used in the discretisation.
- Returns:
vector Interval
- outer_discretisation(n=None)¶
discretisation of a p-box to get intervals based on the scheme of outer approximation
- Parameters:
n (int) – number of steps to be used in the discretisation
Note
the_interval_list will have length one less than that of default p_values (i.e. 100 and 99)
- Returns:
the outer intervals in vec-Interval form
- condensation(n) Self¶
ourter condensation of the pbox to reduce the number of steps and get a sparser staircase pbox
- Parameters:
n (int) – number of steps to be used in the discretisation
Note
Have not thought about a better name so we call it condensation for now. Candidate names include ‘approximation’. It will ouput a p-box and keep steps as 200 for computational consistency.
Example
>>> p.condensation(n=5)
- Returns:
a staircase p-box that looks sparser but has the same number of steps
- condense(n) pyuncertainnumber.pba.dss.DempsterShafer¶
Another condensation function which has steps of n
Compared to the above condensation method that ouputs a p-box and keeps steps as 200 for computational consistency. This one condenses in a more literal manner, as in having n steps in the resulting Dempster-Shafer structure.
- truncate(a, b)¶
Truncate the Pbox to the range [a, b].
example: >>> from pyuncertainnumber import pba >>> p = pba.normal([4, 9], 1) >>> tr = p.truncate(3, 8) >>> fig, ax = plt.subplots() >>> p.plot(ax=ax) >>> tr.plot(ax=ax, fill_color=’r’) >>> plt.show()
- min(other, method='f')¶
Returns a new Pbox object that represents the element-wise minimum of two Pboxes.
- Parameters:
other (-) – Another Pbox object or a numeric value.
method (-) – Calculation method to determine the minimum. Can be one of ‘f’, ‘p’, ‘o’, ‘i’.
- Returns:
Pbox
- max(other, method='f')¶
- get_PI(alpha: numbers.Number = 0.95, style='narrowest') pyuncertainnumber.Interval¶
Compute the predictive interval at the coverage level of alpha
- Parameters:
alpha (Number) – coverage level for the predictive interval, default is 0.95
style (str) – ‘narrowest’ or ‘widest’, default is ‘narrowest’
Note
by default, narrowest predictive interval is returned; when the narrowest does not exist, a warning will the generated and then the widest is returned instead.
Example
>>> from pyuncertainnumber import pba >>> p = pba.normal([10, 15, 1]) >>> p.get_PI(alpha=0.95, style='narrowest')
- straddles(N, endpoints=True) bool¶
Check whether the p-box straddles a number N
- Parameters:
N (float) – the Number to check
endpoints (Boolean) – Whether to include the endpoints within the check
- Returns:
- True
If \(\mathrm{left} \leq N \leq \mathrm{right}\) (Assuming endpoints=True)
- False
Otherwise
Note
This could affect the results of Frechet bounds
- straddles_zero() bool¶
Checks specifically whether \(0\) is within the p-box
- is_zero()¶
- is_nagative()¶
- imp(other)¶
Returns the imposition of self with other pbox
Note
binary imposition between two pboxes only
- _unary_template(f)¶
- exp()¶
exponential function: e^x
- sqrt()¶
square root function: √x
- reciprocal()¶
Calculate the reciprocal of the pbox
Note
the pbox should not straddle zero, otherwise a warning is raised
- log()¶
natural logarithm of the pbox
Note
the pbox must be positive
- sin()¶
- cos()¶
- tanh()¶
- add(other, dependency='f')¶
- sub(other, dependency='f')¶
- mul(other, dependency='f')¶
Multiplication of uncertain numbers with the defined dependency dependency
- div(other, dependency='f')¶
- pow(other, dependency='f')¶
Exponentiation of uncertain numbers with the defined dependency dependency
This suggests that the exponent (i.e. other) can also be an uncertain number.
- balchprod(other)¶
Frechet convolution of two pboxes when any of them straddles zero
- pyuncertainnumber.pba.convert(un)¶
Convert any input un into a Pbox object
Note
theorically ‘un’ can be {Interval, DempsterShafer, Distribution, float, int}
- class pyuncertainnumber.pba.Params¶
- steps = 200¶
- many = 2000¶
- p_lboundary = 0.001¶
- p_hboundary = 0.999¶
- p_values¶
- scott_hedged_interpretation¶
- user_hedged_interpretation¶
- pyuncertainnumber.pba.envelope(*l_uns: pyuncertainnumber.pba.pbox_abc.Pbox | pyuncertainnumber.pba.dss.DempsterShafer | numbers.Number | pyuncertainnumber.pba.intervals.Interval | pyuncertainnumber.pba.distributions.Distribution | pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber, output_type='pbox') pyuncertainnumber.pba.pbox_abc.Staircase | pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber¶
calculates the envelope of constructs only
- Parameters:
l_uns (list) – the components, constructs and uncertain numbers, on which the envelope operation applied on.
output_type (str) – {‘pbox’ or ‘uncertain_number’ or ‘un’} - default is pbox
- Returns:
the envelope of the given arguments, either a p-box or an interval.
Example
>>> from pyuncertainnumber import envelope >>> a = pba.normal(3, 1) >>> b = pba.uniform(5, 8) >>> c = pba.normal(13, 2) >>> t = envelope(a, b, c, output_type='pbox') # or output_type='uncertain_number'
- pyuncertainnumber.pba.imposition(*l_uns: pyuncertainnumber.pba.pbox_abc.Pbox | pyuncertainnumber.pba.dss.DempsterShafer | numbers.Number | pyuncertainnumber.pba.intervals.Interval | pyuncertainnumber.pba.distributions.Distribution | pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber, output_type='pbox') pyuncertainnumber.pba.pbox_abc.Staircase | pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber¶
Returns the imposition/intersection of the list of p-boxes
- Parameters:
l_uns (list) – a list of constructs or UN objects to be mixed
output_type (str) – {‘pbox’ or ‘uncertain_number’ or ‘un’} - default is pbox
- Returns:
Pbox or UncertainNumber
Example
>>> import pyuncertainnumber as pun >>> from pyuncertainnumber import pba >>> a = pba.normal([3, 7], 1) >>> b = pba.uniform([3,5], [6,9]) >>> i = pun.imposition(a, b)
- pyuncertainnumber.pba.stochastic_mixture(*l_uns: pyuncertainnumber.pba.pbox_abc.Pbox | pyuncertainnumber.pba.dss.DempsterShafer | numbers.Number | pyuncertainnumber.pba.intervals.Interval | pyuncertainnumber.pba.distributions.Distribution | pyuncertainnumber.characterisation.uncertainNumber.UncertainNumber, weights=None)¶
it could work for either Pbox, distribution, DS structure or Intervals
- Parameters:
l_uns (-) – list of constructs or uncertain numbers
weights (-) – list of weights
Example
>>> import pyuncertainnumber as pun >>> p = pun.stochastic_mixture([[1,3], [2,4]])
- pyuncertainnumber.pba.stacking(vec_interval: pyuncertainnumber.pba.intervals.Interval | list[pyuncertainnumber.pba.intervals.Interval], *, weights=None, display=False, ax=None, return_type='pbox', **kwargs) pyuncertainnumber.pba.pbox_abc.Pbox¶
stochastic mixture operation of Intervals with probability masses
- Parameters:
vec_interval (-) – list of Intervals or a vectorised Interval
weights (-) – list of weights
display (-) – boolean for plotting
return_type (-) – {‘pbox’ or ‘ds’ or ‘bounds’}
- Returns:
by default a p-box but can return the left and right bound F in eCDF_bundlebounds.
Note
For intervals specifically.
it takes a list of intervals or a single vectorised interval, which is
a different signature compared to the other aggregation functions. - together the interval and masses, it can be deemed that all the inputs required is jointly a DS structure
Example
>>> stacking([[1,3], [2,4]], weights=[0.5, 0.5], display=True)
- pyuncertainnumber.pba.mixture_pbox(*l_pboxes, weights=None, display=False) pyuncertainnumber.pba.pbox_abc.Pbox¶
- pyuncertainnumber.pba.mixture_ds(*l_ds, display=False) pyuncertainnumber.pba.dss.DempsterShafer¶
mixture operation for DS structure
- pyuncertainnumber.pba.env_samples(data: numpy.typing.ArrayLike, output_type='pbox', ecdf_choice='canonical')¶
nonparametric envelope function directly from data samples
- Parameters:
data (ArrayLike) – Each row represents a distribution, on which the envelope operation applied.
output_type (str) – {‘pbox’ or ‘cdf’} default is pbox cdf is the CDF bundle
ecdf_choice (str) – {‘canonical’ or ‘staircase’}
Note
envelope on a set of empirical CDFs
- pyuncertainnumber.pba.env_ecdf_sep(*ecdfs, output_type='pbox', ecdf_choice='canonical')¶
nonparametric envelope function for separate empirical CDFs
- pyuncertainnumber.pba.env_am(n_pars: numpy.typing.ArrayLike) numpy.ndarray¶
bespoke function used for am metric case
- Parameters:
n_pars (ArrayLike) – (n_sam, 2) of tuple (mu, sigma) which may be a tensor
- pyuncertainnumber.pba.env_pbox_am(n_mean: numpy.typing.ArrayLike, n_std: numpy.typing.ArrayLike) numpy.ndarray¶
bespoke function used for am metric case
- Parameters:
n_mean (ArrayLike) – (n_sam,) of mean values which may be a tensor
n_std (ArrayLike) – (n_sam,) of standard deviation values which may be a tensor
- pyuncertainnumber.pba.KS_bounds(s: numpy.typing.ArrayLike, alpha: float, display=True, output_type='bounds') tuple[pyuncertainnumber.pba.ecdf.eCDF_bundle] | pyuncertainnumber.pba.pbox_abc.Pbox | pyuncertainnumber.UncertainNumber¶
construct free pbox from sample data by Kolmogorov-Smirnoff confidence bounds
- Parameters:
s (ArrayLike) – sample data, precise and imprecise
dn (float) – KS critical value at a significance level and sample size N;
output_type (str) – A choice between {‘bounds’, ‘pbox’, ‘un’}, default=’bounds’ which returns two eCDF bundles as bounds; ‘pbox’ to return a pbox object; ‘un’ to return an uncertain number object.
- Returns:
a tuple of two CDF bounds, i.e. upper and lower (eCDF_bundle objects), or a Pbox object, or an UncertainNumber object the return type is controlled by the output_type argument.
Note
By default the function returns two eCDF bundles as the extreme bounds. With the upper and lower bounds, a free pbox can be constructed.
Example
>>> # both precise data (e.g. numpy array) and imprecise data (e.g. a vector of interval) are supported >>> precise_data = np.random.normal(0, 1, 100) # precise data case >>> ub, lb = pba.KS_bounds(precise_data, alpha=0.025, display=True)
>>> # alternatively, an uncertain number or a p-box can be returned >>> pba.KS_bounds(precise_data, alpha=0.025, display=False, output_type='pbox') # return a pbox object >>> pba.KS_bounds(precise_data, alpha=0.025, display=False, output_type='un') # return an uncertain number object
>>> # imprecise data case >>> impre_data = pba.I(lo = precise_data -0.5, hi = precise_data + 0.5) >>> ub, lb = pba.KS_bounds(impre_data, alpha=0.025, display=True)
Kolmogorov-Smirnoff confidence bounds illustration with precise and imprecise data.¶