Uncertainty characterisation¶
Variability and incertitude¶
Modern risk analysts distinguish between variability and incertitude. Variability (also called randomness, aleatory uncertainty, or irreducible uncertainty) arises from natural stochasticity, environmental or structural variation across space or time, manufacturing heterogeneity among components or individuals. Incertitude, also called ignorance, epistemic uncertainty, subjective uncertainty or reducible uncertainty, arises from incompleteness of knowledge. Sources of incertitude include measurement uncertainty, small sample sizes, and data censoring, ignorance about the details of physical mechanisms and processes.
For an engineering analysis, the challenge lies in formulating suitable uncertainty models given available information, without introducing unwarranted assumptions. However, the available information is often vague, ambiguous, or qualitative. Available data are frequently limited and of poor quality, giving rise to challenges in eliciting precise probabilistic specifications. Solutions to this problem are discussed in the literature, under the framework of imprecise probability, from various perspectives using different mathematical concepts, including for example random sets, evidence theory, fuzzy stochastic concepts, info-gap theory, and probability bounds analysis.
Tip
It is suggested to use interval analysis for propagating ignorance and the methods of probability theory for propagating variability.
Bounding distributional parameters¶
The mean of a normal distribution may be elicited from an expert, but this expert cannot be precise to a certain value but rather give a range based on past experience.
To comprehensively characterise a pbox, specify the bounds for the parameters along with many other ancillary fields.
from pyuncertainnumber import UncertainNumber as UN
e = UN(
name='elas_modulus',
symbol='E',
units='Pa',
essence='pbox',
distribution_parameters=['gaussian', ([0,12],[1,4])])
In cases where one wants to do computations quickly.
import pyuncertainnumber as pun
un = pun.norm([0,12],[1,4])
For low-level controls and customisation
from pyuncertainnumber import pba
pbox = pba.normal([0,12],[1,4])
Tip
The different sub-types of uncertain number can normally convert to one another (though may not be one by one), ergo the uncertain number been said to be a unified representation.
See also
See also the tutorial the What is an uncertain number to get started.
Aggregation of multiple sources of information¶
Expert elicitation has been a challenging topic, especially when knowledge is limited and measurements are sparse. Multiple experts may not necessarily agree on the choice of elicited probability distributions, which leads to the need for aggregation. Below shows two situations for illustration.
Assume the expert opinions are expressed in closed intervals. There may well be multiple such intervals from different experts and these collections of intervals can be overlapping, partially contradictory or even completely contradictory. Their relative credibility may be expressed in probabilities. Essentially such information creates a Dempster-Shafer structure. On the basis of a mixture operation, such information can be aggregated into a p-box.
See also
See also the tutorial uncertainty aggregation to get started.
Inter-variable dependence¶
P-box arithmetic also extends the convolution of probability distributions which has typically been done with the independence assumption. However, often in engineering modelling practices independence is assumed for mathematical easiness rather than warranted. Fortunately, the uncertainty about the dependency between random variables can be characterised by the probability bounds, as seen below. It should be noted that such dependency bound does not imply independence.
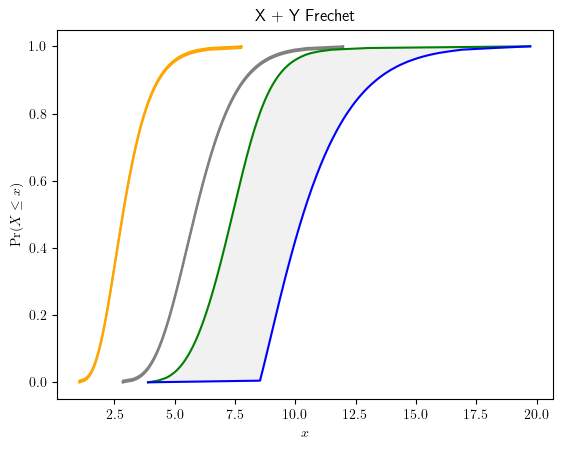
See also
See also the tutorial depenency structure to get started .
Known statistical properties¶
When the knowledge of a quantity is limited to the point where only some statistical information is available, such as the min, max, median etc. but not about the distribution and parameters, such partial information can serve as constraints to bound the underlying distribution:
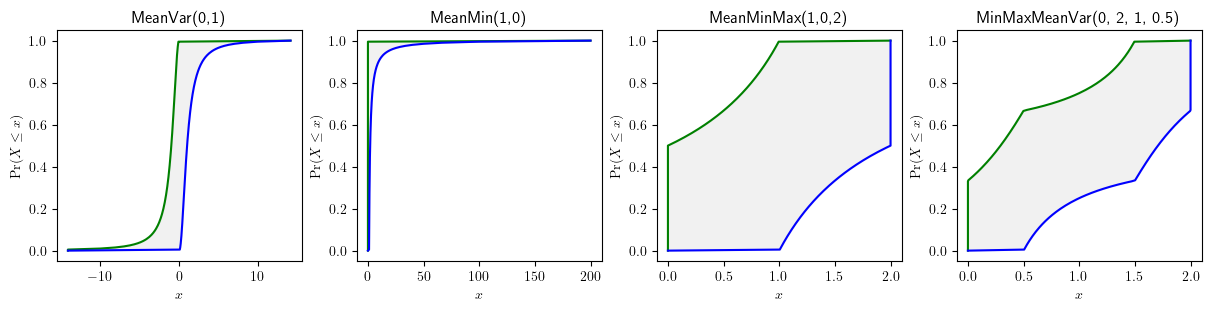
See also
See also the tutorial characterise as you go to get started.
Hedged numerical expression¶
Sometimes only purely qualitative information is available. An important part of processing elicited numerical inputs is an ability to quantitatively decode natural-language words, the linguistic information, that are commonly used to express or modify numerical values. Some examples include ‘about’, ‘around’, ‘almost’, ‘exactly’, ‘nearly’, ‘below’, ‘at least’, ‘order of’, etc. A numerical expression with these approximators are called hedges. Extending upon the significant-digit convention, a series of interval interpretations of common hedged numerical expressions are proposed.
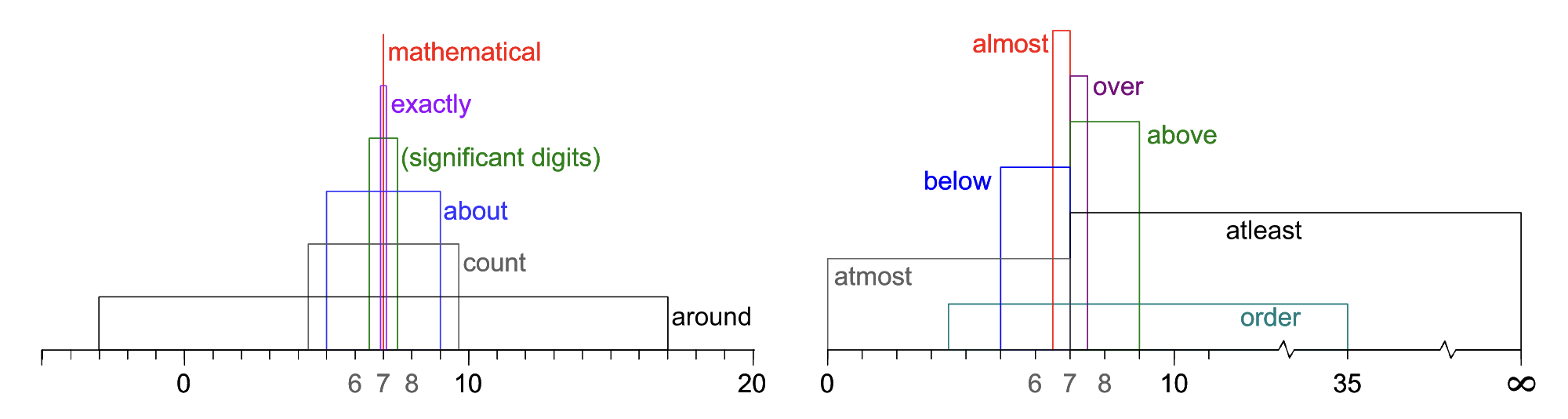
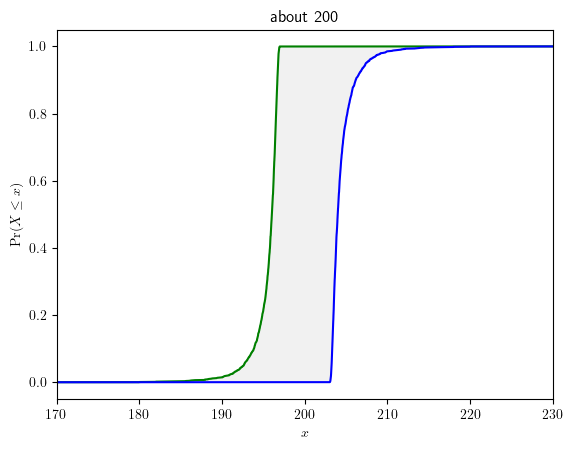
Besides intervals, PyUncertainNumber also supports interpreting hedged expressions into p-boxes. As an example, assume one wants to find out what “about” is about in terms of the uncertainty. The syntax and result is shown below:
import pyuncertainnumber as pun
pun.hedge_interpret('about 200', return_type='pbox').display()
See also
See also the tutorial Interpret linguistic hedges to get started.
Data uncertainty¶
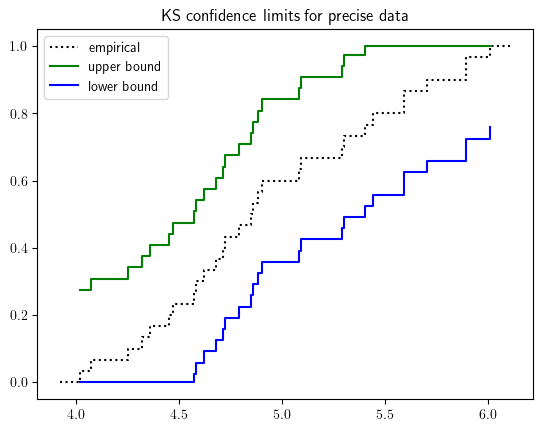
Measurement uncertainty is another main source uncertainty of data uncertainty besides sampling uncertainty. Point estimates from samples vary from one to another. We will typically use confidence intervals (as interval estimators) to account for the sampling uncertainty. As an example, PyUncertainNumber provides support for Kolmogorov–Smirnov (KS) confidence limits to infer the confidence limits for empirical cumulative distribution function.
See also
See also the confidence box for a distributional estimator.
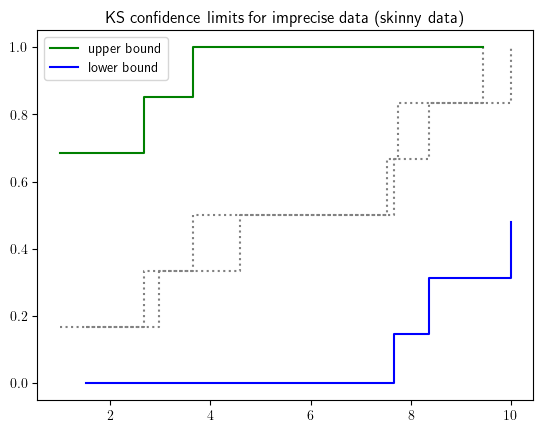
As to measurement uncertainty, Intervals turn out to be a natural means of mathematical construct for imprecise data due to the common understanding of margin of error, which leads to the midpoint notation of an interval object. PyUncertainNumber provides an extension of the Kolmogorov–Smirnov confidence limits for interval-valued data as well. The lower figure shows such confidence limits for the skinny data.